Statystyki jako klucz do rozwiązywania problemów z wydajnością
Trendem współczesności jest wzrost przepływów informacji wewnątrz firmy, osiągany dzięki wielu czynnikom: wzrostowi liczby użytkowników, wzrostowi liczby zautomatyzowanych procesów biznesowych, wzrostowi liczby jednostek biznesowych (oddziały, parkiety, dodatkowe biura, magazyny). Należy stale mieć dostęp do niezbędnych informacji, optymalność decyzji, od niej zależy rentowność firmy. Organizowanie ciągłego dostępu nie zawsze jest możliwe. Może to wynikać z awarii oprogramowania i sprzętu przy różnych obciążeniach (środki proceduralne, na przykład w systemie 1C 8.x, może to być zamknięcie miesiąca, obliczenie kosztów, obliczenie listy płac, sprzedaż przedświąteczna, promocje itp.). Jak zrozumieć przyczyny problemów z wydajnością i jak najszybciej je rozwiązać?
W tym celu za pomocą różnych narzędzi zbieraj informacje o wydajności systemu informacyjnego (w naszym przypadku używamy monitorowania wydajności PerfExpert mając ścisłą integrację z takimi systemami informacyjnymi, jak 1C 7.7, 1C 8.1, 1C 8.2, 1C 8.3) i analizować w poszukiwaniu „wąskich gardeł” w wydajności. Biorąc pod uwagę, że informacje są gromadzone w dużych ilościach z różnych źródeł (liczniki wydajności systemu Windows, MS SQL Server, procesy ładowania SQL Server, ciężkie i nieoptymalne zapytania SQL, ładowanie sesji użytkownika), należy je pogrupować i uszeregować według ważności.
W naszej praktyce analiza i, co najważniejsze, wizualna prezentacja informacji umożliwiła znalezienie wzorca zachowania, a to z kolei pozwoliło nam przejść do przyczyny niepowodzeń.
Podam jeden przykład: jeden z naszych cenionych klientów skarżył się na system informacyjny, który zawisł podczas otwierania okna dokumentu „Faktura, którą można wydać”, jak zwykle, przeanalizowaliśmy kod za pomocą wbudowanego debugera - nie znaleźliśmy żadnych problemów, przeprowadziliśmy testy syntetyczne - hamowanie prawie nigdy nie miało miejsca, nie opracowali jeszcze leczenia, które w równym okresie otworzyło okno dokumentu i utrzymało czas trwania tych odkryć. Na pierwszy rzut oka nie było „przestępstwa”, mniej niż 2% odkryć zostało otwartych niedopuszczalnie długo. Ale gdy tylko stworzyliśmy diagram w Excelu na podstawie danych, zauważyliśmy interesujący wzór.
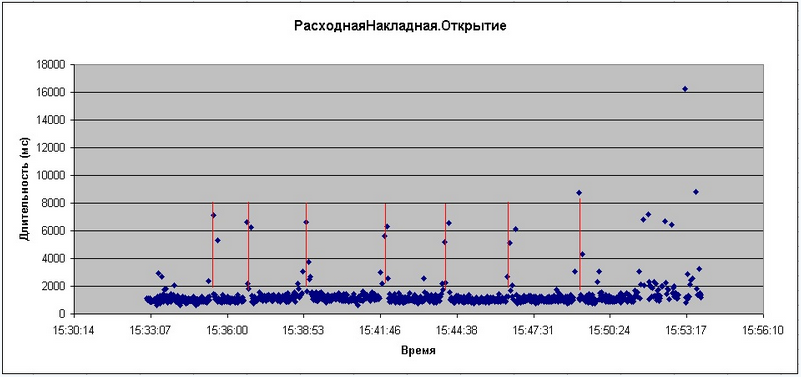
Rys.1. Czas trwania formularza otwierającego dokument „Faktura wydatków”
Jak widać na rysunku 1, tylko niewielka liczba otwarć formularzy dokumentów jest znacznie wolniejsza niż zwykle, ale zwróć uwagę, że momenty tych spowolnień są powtarzane z prawie taką samą częstotliwością - to umożliwiło znalezienie przyczyny powolnej pracy - zadania w tle, które powtarza się co 2 minuty. Korzystając z tego przykładu, chciałbym pokazać, jak ważna jest prawidłowa i skuteczna praca z informacjami statystycznymi.
Jako drugi przykład chciałbym pokazać, jak nasza firma przeprowadza analizy i rozwiązuje problemy z produktywnością klientów. Nie jest tajemnicą, że podczas przesłuchiwania użytkowników narzekają na wiele operacji: zarówno szybkie wykonywanie dokumentów, wykonywanie raportów i przetwarzanie, jak i wyświetlanie wiadomości z blokadami lub po prostu odkładanie formularzy interfejsów systemów informatycznych. Oczywiście w naszej analizie uwzględniamy informacje od użytkownika, ale przede wszystkim staramy się brać pod uwagę rzeczywiste dane statystyczne z systemów informacyjnych i serwerów baz danych.
Na przykład użytkownik skarży się na czas trwania raportu X. Oczywiście, początkowo chciałbym przeanalizować kod IP, na którym został napisany raport. Ale w tej sytuacji zalecamy, aby najpierw sprawdzić dane monitorowania wydajności i ustalić, czy w momencie wykonywania raportu wystąpił niedobór zasobów serwera (zwykle serwera bazy danych). Jeśli brakowało zasobów, zamiast analizować kod implementacji raportu, zalecamy przeanalizowanie przyczyny braku zasobów, a mianowicie, które polecenia SQL / zapytania zużyły zasoby. W większości przypadków te zapytania SQL nie są bezpośrednio związane z raportem X, ale są operacjami innych firm (monity ekranowe, procedury interfejsu, raporty operacyjne). Muszą być zoptymalizowane.
Aby wyszukać podobne zapytania SQL, używamy formularza do śledzenia zapytań dotyczących monitorowania wydajności. PerfExpert .
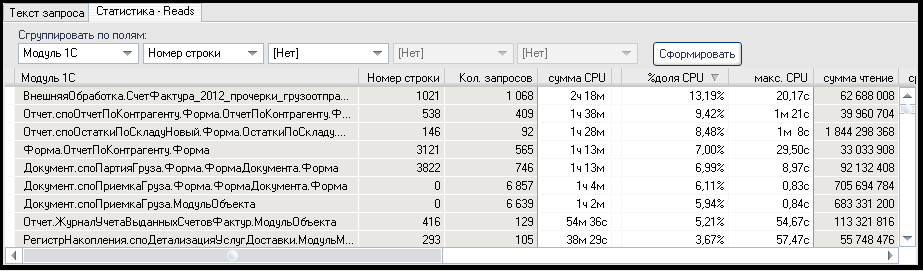
Rys.2. Statystyki ciężkich zapytań SQL w zakresie modułów i linii kodu 1C
Jak pokazano na rysunku 2, pierwsza linia kodu aplikacji stanowi 13,19% całkowitego obciążenia procesora na serwerze bazy danych MS SQL, druga linia to 9,42%. Jeśli więc nie ma wystarczających zasobów procesora do szybkiej realizacji operacji użytkownika, zaleca się zoptymalizowanie pierwszych 2 linii - w sumie zapewniają one prawie 23% całkowitego obciążenia procesora. Sytuacja jest taka sama z dyskiem / pamięcią i analiza powinna być przeprowadzona podobnie.
Mam nadzieję, że ten materiał będzie przydatny w pracy i zrozumienie znaczenia pracy i analizy informacji statystycznych. Możesz dowiedzieć się więcej o używanym przez nas narzędziu do monitorowania systemu informacyjnego PERFEXPERT http://www.softpoint.ru/perfexpert-administrirovanie-serverov oraz o świadczonych przez nas usługach http://www.softpoint.ru/vse-it-uslugi-dly-biznesa