Внутренние компоненты Microsoft SQL Server 2012: специальное хранилище
- Данные больших объектов ограниченной длины (данные переполнения строк)
- Таблица 8-1 Первые 16 байтов указателя переполнения строки
- Данные больших объектов неограниченной длины
- Перечисление 8-1, Хранящее данные большого объекта на двух типах страниц
- Хранение данных больших объектов в строке данных
- Перечисление 8-2, Находящее основную информацию для таблицы HasText
- Хранение данных MAX-длины
- Добавление данных в столбец LOB
В этой главе из Microsoft SQL Server 2012 Internals рассказывается о том, как SQL Server хранит данные, которые не используют типичный формат записи FixedVar , и данные, которые не вписываются в обычную страницу данных 8 КБ.
Кален Делани
В предыдущих главах обсуждалось хранение «обычных строк» для данных и индексной информации. (Глава 7, «Индексы: внутреннее устройство и управление», также рассмотрела совершенно другой способ хранения индексов: использование хранилищ столбцов, которые вообще не хранятся в строках.) В главе 6, «Хранение таблиц», объяснялось, что обычные строки в формате под названием FixedVar . SQL Server предоставляет способы хранения данных в другом формате, называемом дескриптором столбца (CD). Он также может хранить специальные значения в формате FixedVar или CD, которые не помещаются на обычных страницах размером 8 КБ.
В этой главе описываются данные, которые превышают типичные ограничения на размер строки и хранятся как данные с переполнением строки или данные большого объекта (LOB). Вы узнаете о двух дополнительных методах хранения данных на реальных страницах данных, представленных в Microsoft SQL Server 2008: один использует новый тип сложного столбца с обычной строкой данных (разреженные столбцы), а другой - новый компакт-диск. формат (сжатые данные). В этой главе также обсуждаются данные FILESTREAM, функция, представленная в SQL Server 2008, которая позволяет получать доступ к данным из файлов операционной системы, как если бы они были частью ваших реляционных таблиц, и FileTables, новая функция в SQL Server 2012, которая позволяет создавать таблица, содержащая как данные FILESTREAM, так и метаданные атрибута файла Windows.
Наконец, в этой главе рассматривается возможность SQL Server разделять данные на разделы. Хотя это не меняет формат данных в строках или на страницах, он меняет метаданные, которые отслеживают, какое место выделено для каких объектов.
SQL Server 2012 имеет два специальных формата для хранения данных, которые не помещаются на обычной странице данных 8 КБ. Эти форматы позволяют хранить строки, размер которых превышает максимальный размер строки в 8 060 байт. Как обсуждалось в главе 6, это максимальное значение размера строки включает в себя несколько байтов служебных данных, сохраняемых со строкой на физических страницах, поэтому общий размер всех определенных столбцов таблицы должен быть немного меньше этого количества. На самом деле, сообщение об ошибке, которое вы получите, если попытаетесь создать таблицу с большим количеством байтов, чем допустимый максимум, очень специфично. Если вы выполните следующую инструкцию CREATE TABLE с определениями столбцов, которые в сумме составляют ровно 8 060 байт, вы получите сообщение об ошибке, показанное здесь:
ИСПОЛЬЗОВАНИЕ testdb; GO CREATE TABLE dbo.bigrows_fixed (символ (3000), символ (3000), символ (2000), символ (60)); Сообщение 1701, Уровень 16, Состояние 1, Строка 1 Не удалось создать или изменить таблицу 'bigrows', поскольку минимальный размер строки составлял бы 8067, включая 7 байтов внутренних издержек. Это превышает максимально допустимый размер строки таблицы в 8060 байт.
В этом сообщении вы видите количество служебных байтов (7), которые SQL Server хочет сохранить вместе с самой строкой. Дополнительные 2 байта используются для информации о смещении строки в конце страницы, но эти байты не включены в это общее количество.
Данные больших объектов ограниченной длины (данные переполнения строк)
Одним из способов превышения этого ограничения размера в 8 060 байт является использование столбцов переменной длины, поскольку для данных переменной длины SQL Server 2005 и более поздние версии могут хранить столбцы на специальных страницах с переполнением строк, если все столбцы фиксированной длины вписывается в обычный предел размера в строке. Поэтому вам нужно посмотреть на таблицу со всеми столбцами переменной длины. Обратите внимание, что хотя в моем примере используются все столбцы varchar , столбцы других типов данных также могут храниться на страницах с данными переполнения строк. Эти другие типы данных включают столбцы varbinary, nvarchar и sqlvariant , а также столбцы, в которых используются определяемые пользователем типы данных CLR. Следующий код создает таблицу со строками, максимальная заданная длина которых намного превышает 8 060 байт:
ИСПОЛЬЗОВАНИЕ testdb; CREATE TABLE dbo.bigrows (varchar (3000), b varchar (3000), c varchar (3000), d varchar (3000));
Фактически, если вы запустите этот оператор CREATE TABLE в SQL Server 7.0, вы получите ошибку, и таблица не будет создана. В SQL Server 2000 таблица была создана, но вы получили предупреждение о том, что вставки или обновления могут завершиться ошибкой, если размер строки превышает максимальный.
В SQL Server 2005 и более поздних версиях не только можно было создать предыдущую таблицу dbo.bigrows , но также можно вставить строку с размерами столбцов, которые составляют более 8 060 байт, с помощью простого INSERT :
INSERT INTO dbo.bigrows SELECT REPLICATE ('e', 2100), REPLICATE ('f', 2100), REPLICATE ('g', 2100), REPLICATE ('h', 2100);
Чтобы определить, хранит ли SQL Server какие-либо данные на страницах с данными переполнения строк для конкретной таблицы, вы можете выполнить следующий запрос на выделение из главы 5 «Ведение журнала и восстановление»:
ВЫБЕРИТЕ имя_объекта (object_id) AS имя, partition_id, номер_раздела AS pnum, строки, alloc_unit_id AS au_id, type_desc как page_type_desc, total_pages AS-страницы ОТ sys.partitions p ПРИСОЕДИНЯЙТЕСЬ sys.allocation_units a ON p.partition_id = a.container_id 'dbo.bigrows');
Этот запрос должен возвращать вывод, аналогичный показанному здесь:
имя partition_id pnum строк au_id page_type_desc страницы ---- ----------------- ---- ---- -------------- --- ---------------- ----- bigrows 72057594039238656 1 1 72057594043957248 IN_ROW_DATA 2 bigrows 72057594039238656 1 1 72057594044022784 ROW_OVERFLOW_DATA 2
Вы можете видеть, что есть две страницы для одной строки обычных данных в строке и две страницы для одной строки данных переполнения строки. Кроме того, вы можете использовать функцию sys.dm_db_database_page_allocations и просматривать четыре страницы по отдельности:
ВЫБЕРИТЕ alloc_page_file_id в качестве PageFID, alloc_page_page_id в качестве PagePID, object_id в качестве ObjectID, partition_id AS PartitionID, alloc_unit_type_desc в качестве AU_type, page_type в качестве PageType FROM sys.dm_db_database_page_allocations (db_id ('objectdll' null, null_dll), (null_d) ', DID_DIBLE_DIBLE_DIBLE_DIBLE_DIBLE_DI_DIL_DIL_DIL_DIL_DIL_DIL_DIL_DIL_DIL_DIL_DIL_DIL_DIF );
Вы должны увидеть четыре строки, по одной для каждой страницы, которые выглядят примерно так:
PageFID PagePID ObjectID PartitionID AU_type PageType ------- ----------- ----------- ----------- ---- --------------- ----------- 1 303 1653580929 1 IN_ROW_DATA 10 1 302 1653580929 1 IN_ROW_DATA 1 1 297 1653580929 1 ROW_OVERFLOW_DATA 10 1 296 1653580929 1 ROW_OVERFLOW_DATA 3
Конечно, ваши фактические значения идентификатора будут отличаться, но значения AU -type и PageType должны быть одинаковыми, и вы должны получить четыре строки, указывающие, что четыре страницы принадлежат таблице bigrows . Две страницы предназначены для данных переполнения строк, а две - для данных в строке. Как вы видели в главе 7, значения PageType имеют следующие значения.
PageType = 1, Страница данных
PageType = 2, страница указателя
PageType = 3, LOB или страница переполнения строки, TEXT_MIXED
PageType = 4, LOB или страница переполнения строки, TEXT_DATA
PageType = 10, страница IAM
Вы узнаете больше о различных типах LOB-страниц в следующем разделе «Данные больших объектов неограниченной длины».
Вы можете видеть одну страницу данных и одну страницу IAM для данных в строке, и одну страницу данных и одну страницу IAM для данных переполнения строки. С результатами sys.dm_db_database_page_allocations вы можете просмотреть содержимое страницы с помощью DBCC PAGE . На странице данных для данных в строке вы увидите три из четырех значений столбца varchar , а четвертый столбец будет сохранен на странице данных для данных переполнения строки. Если вы запустите DBCC PAGE для страницы данных, на которой хранятся данные в строке (стр. 1: 302 в предыдущем выводе), обратите внимание, что это не обязательно четвертый столбец в порядке столбцов, который хранится вне строки. (Я не буду показывать вам все содержимое строк, потому что одна строка заполняет почти всю страницу.) Посмотрите на страницу данных в строке, используя DBCC PAGE, и обратите внимание на столбец с e , столбец с g и столбец с ч . Столбец с f переместился в новую строку. Вместо этого столбца вы можете увидеть байты, показанные здесь:
65020000 00010000 00c37f00 00340800 00280100 00010000 0067
Включены последний байт с e (шестнадцатеричный код ASCII 65) и первый байт с g (шестнадцатеричный код ASCII 67), а между ними находятся 24 других байта (жирный шрифт). Байты с 16 по 23 (с 17 по 24 байты) из этих 24 байтов обрабатываются как 8-байтовое числовое значение: 2801000001000000 (полужирный курсив). Необходимо изменить порядок следования байтов и разбить его на 2-байтовое шестнадцатеричное значение для номера слота, 2-байтовое шестнадцатеричное значение для номера файла и 4-байтовое шестнадцатеричное значение для номера страницы. Таким образом, номер слота 0x0000 для слота 0, потому что этот переполняющий столбец является первыми (и единственными) данными на странице переполнения строк. У вас есть 0x0001 (или 1) для номера файла и 0x00000128 (или 296) для номера страницы. Вы видели эти одинаковые номера файлов и страниц при использовании sys.dm_db_database_page_allocations .
Таблица 8-1 описывает первые 16 байтов в строке.
Таблица 8-1 Первые 16 байтов указателя переполнения строки
Б
Шестнадцатеричное значение
Десятичное значение
Имея в виду
0
0x02
2
Тип специального поля: 1 = LOB2 = переполнение
1-2
0x0000
0
Уровень в B-дереве (всегда 0 для переполнения)
3
0x00
0
неиспользуемый
4-7
0x00000001
1
Последовательность: значение, используемое оптимистическим управлением параллелизмом для курсоров, которое увеличивается каждый раз, когда обновляется большой объект или столбец переполнения
8-11
0x00007fc3
32707
Отметка времени: случайное значение, используемое DBCC CHECKTABLE, которое остается неизменным в течение времени жизни каждого столбца большого объекта или переполнения
12-15
0x00000834
2100
длина
SQL Server хранит столбцы переменной длины на страницах переполнения строк только при определенных условиях. Определяющим фактором является сама длина строки. Насколько полно обычная страница, в которую SQL Server пытается вставить новую строку, не имеет значения; SQL Server строит строку как обычно и сохраняет некоторые из ее столбцов на страницах переполнения, только если самой строке требуется более 8 060 байт.
Каждый столбец в таблице либо полностью в строке, либо полностью вне строки. Это означает, что столбец переменной длины 4000 байтов не может иметь половину своих байтов на обычной странице данных и половину на странице переполнения строк. Если длина строки составляет менее 8 060 байт, а страница, на которой SQL Server пытается вставить строку, не имеет места, применяются обычные алгоритмы разделения страниц (описанные в главе 7).
Одна строка может занимать много страниц с переполнением строк, если она содержит много больших столбцов переменной длины. Например, вы можете создать таблицу dbo.hugerows и вставить в нее одну строку следующим образом:
CREATE TABLE dbo.hugerows (varchar (3000), b varchar (8000), c varchar (8000), d varchar (8000)); INSERT INTO dbo.hugerows SELECT REPLICATE ('a', 3000), REPLICATE ('b', 8000), REPLICATE ('c', 8000), REPLICATE ('d', 8000);
Подстановка огромных чисел для больших чисел для запроса на выделение, показанного ранее, дает следующие результаты:
имя partition_id pnum строк au_id page_type_desc страниц -------- ----------------- ---- ---- ---------- ------- ----------------- ----- hugerows 72057594039304192 1 1 72057594044088320 IN_ROW_DATA 2 hugerows 72057594039304192 1 1 72057594044153856 ROW_OVERFLOW_DATA 4
Выходные данные показывают четыре страницы для информации о переполнении строк, одну для страницы IAM переполнения строк и три для столбцов, которые не помещаются в обычной строке. Число больших столбцов переменной длины, которые может иметь таблица, не безгранично, хотя и достаточно велико. Таблица ограничена 1024 столбцами, которые могут быть превышены при использовании разреженных столбцов, как будет обсуждаться далее в этой главе. Тем не менее, еще один предел достигнут до этого. Когда столбец должен быть перемещен с обычной страницы на страницу переполнения строк, SQL Server сохраняет указатель на информацию о переполнении строк как часть исходной строки, которую вы видели в выводе DBCC ранее как 24 байта, и строку по-прежнему требуется 2 байта в массиве смещения столбца для каждого столбца переменной длины, независимо от того, хранится ли столбец переменной длины в строке. Таким образом, 308 оказывается максимальным числом переполняемых столбцов, которое вы можете иметь, и такая строка требует 8,008 байтов только для 26 служебных байтов для каждого переполняющегося столбца в строке.
В некоторых случаях, если большой столбец переменной длины сокращается, его можно переместить обратно в обычную строку. Однако для эффективности, если уменьшение составляет всего несколько байтов, SQL Server не беспокоится о проверке. Только когда столбец, сохраненный на странице переполнения строк, уменьшается более чем на 1000 байтов, SQL Server даже рассматривает возможность проверки того, может ли столбец теперь поместиться на обычной странице данных. Вы можете наблюдать это поведение, если ранее вы создали таблицу dbo.bigrows для предыдущего примера и вставили только одну строку с 2100 символами в каждом столбце.
Следующее обновление уменьшает размер первого столбца на 500 байт и уменьшает размер строки до 7900 байт, которые должны уместиться на одной странице данных:
ОБНОВЛЕНИЕ bigrows SET a = replicate ('a', 1600);
Однако если вы повторно запустите запрос на выделение, вы все равно увидите две страницы переполнения строк: одну для данных переполнения строк и одну для страницы IAM. Теперь уменьшите размер первого столбца более чем на 1000 байтов и повторно запустите запрос выделения:
ОБНОВЛЕНИЕ bigrows SET a = 'aaaaa';
Теперь вы должны увидеть только три страницы для таблицы, потому что больше нет страницы данных переполнения строк. Страница IAM для страниц данных переполнения строк не была удалена, но у вас больше нет страницы данных для данных переполнения строк.
Помните, что хранилище данных с переполнением строк применяется только к столбцам данных переменной длины, которые определены как не более обычного максимального значения переменной длины, равного 8000 байтов на столбец. Кроме того, чтобы сохранить столбец переменной длины на странице переполнения строк, необходимо выполнить следующие условия.
Все столбцы фиксированной длины, включая служебные байты, должны содержать не более 8 060 байтов. (Указатель на каждый столбец переполнения строки добавляет 24 байта служебной информации к строке.)
Фактическая длина столбца переменной длины должна быть больше 24 байтов.
Столбец не должен быть частью ключа кластеризованного индекса.
Если у вас есть отдельные столбцы, в которых может потребоваться хранить более 8000 байтов, следует использовать столбцы LOB ( текст, изображение или текст ) или типы данных MAX .
Данные больших объектов неограниченной длины
Если таблица содержит устаревшие типы данных больших объектов ( текстовые, текстовые или графические ), по умолчанию фактические данные не сохраняются на обычных страницах данных. Как и данные с переполнением строк, данные больших объектов хранятся в своем собственном наборе страниц, а запрос на выделение показывает вам страницы для данных больших объектов, а также страницы для обычных данных в строках и данных с переполнением строк. Для столбцов больших объектов SQL Server хранит 16-байтовый указатель в строке данных, который указывает, где можно найти фактические данные. Хотя стандартное поведение заключается в сохранении всех данных больших объектов из строки данных, SQL Server позволяет изменить механизм хранения, установив параметр таблицы, позволяющий хранить данные больших объектов в самой строке данных, если она достаточно мала. Обратите внимание, что нет базы данных или настройки сервера для управления хранением небольших столбцов больших объектов на страницах данных; это управляется как опция таблицы.
16-байтовый указатель указывает на страницу (или первую из набора страниц), где можно найти данные. Эти страницы имеют размер 8 КБ, как и любая другая страница в SQL Server, и отдельные страницы текста, ntext и изображения не ограничиваются хранением данных только для одного экземпляра столбца text, ntext или image . Страница текста, текста или изображения может содержать данные из нескольких столбцов и из нескольких строк; страница может даже содержать текстовые, текстовые и графические данные. Однако одна страница текста или изображения может содержать только данные текста или изображения из одной таблицы. (Более конкретно, одна страница с текстом или изображением может содержать только данные текста или изображения из одного раздела таблицы, что должно стать понятным, когда в конце этой главы обсуждается разделение метаданных.)
Коллекция из 8 КБ страниц, которые составляют столбец больших объектов, не обязательно расположены рядом друг с другом. Страницы логически организованы в виде структуры B-дерева, поэтому операции, начинающиеся в середине строки LOB, очень эффективны. Структура B-дерева немного меняется в зависимости от того, является ли объем данных меньше или больше 32 КБ. (Увидеть Рисунок 8-1 для общей структуры.) B-деревья подробно обсуждались при описании индексов в главе 7.
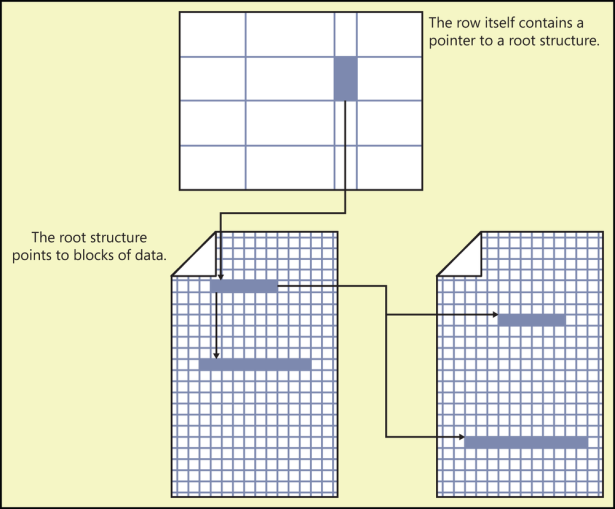
Рисунок 8-1 Текстовый столбец, указывающий на B-дерево, которое содержит блоки данных.
Если объем данных больших объектов меньше 32 КБ, текстовый указатель в строке данных указывает на корневую текстовую структуру размером 84 байта. Это формирует корневой узел структуры B-дерева. Корневой узел указывает на блоки текста, текста или изображения . Хотя данные для столбцов больших объектов логически расположены в B-дереве, как корневой узел, так и отдельные блоки данных физически распределены по страницам больших объектов для таблицы. Они размещены везде, где есть свободное место. Размер каждого блока данных определяется размером, записанным приложением. Небольшие блоки данных объединяются для заполнения страницы. Если объем данных меньше 64 байт, все они хранятся в корневой структуре.
Если объем данных для одного вхождения столбца большого объекта превышает 32 КБ, SQL Server начинает создавать промежуточные узлы между блоками данных и корневым узлом. Корневая структура и блоки данных чередуются по всему тексту и изображениям страниц. Промежуточные узлы, однако, хранятся на страницах, которые не разделяются между вхождениями столбцов текста или изображения . Каждая страница, хранящая промежуточные узлы, содержит только промежуточные узлы для одного столбца текста или изображения в одной строке данных.
SQL Server может хранить корневой каталог больших объектов и фактические данные больших объектов на страницах двух разных типов. Один из них, называемый TEXT_MIXED , позволяет данным больших объектов из нескольких строк использовать одни и те же страницы. Однако когда объем ваших текстовых данных превышает 40 КБ, SQL Server начинает выделять целые страницы одному значению большого объекта. Эти страницы называются страницами TEXT_DATA .
Вы можете увидеть это поведение, создав таблицу с текстовым столбцом, вставив значение менее 40 КБ, а затем одно больше 40 КБ, и, наконец, изучив информацию, возвращаемую sys.dm_db_database_page_allocations (см. Листинг 8-1).
Перечисление 8-1, Хранящее данные большого объекта на двух типах страниц
ЕСЛИ OBJECT_ID ('textdata') НЕ НУЛЯЕТ DROP TABLE textdata; GO CREATE TABLE textdata (большой текст); GO INSERT INTO textdata SELECT REPLICATE (convert (varchar (MAX), 'a'), 38000); GO ВЫБРАТ ВЫБРАТЬ_Данный_страница_идентификатора в качестве PageFID, выделенный_страница_страницы_страницы в качестве PagePID, Идентификатор_объекта в качестве идентификатора_объекта, идентификатор_раздела AS, Идентификатор_рассылки_unit_type_desc в качестве AU_type, тип_страницы_страницы в качестве PageType FROM sys.dm_db_database_page_allocations (текстовый объект, dll_DID) «); GO INSERT INTO textdata SELECT REPLICATE (convert (varchar (MAX), 'a'), 41000); GO ВЫБРАТ ВЫБРАТЬ_Данный_страница_идентификатора в качестве PageFID, выделенный_страница_страницы_страницы в качестве PagePID, Идентификатор_объекта в качестве идентификатора_объекта, идентификатор_раздела AS, Идентификатор_рассылки_unit_type_desc в качестве AU_type, тип_страницы_страницы в качестве PageType FROM sys.dm_db_database_page_allocations (текстовый объект, dll_DID) «); ИДТИ
Операторы INSERT в листинге 8-1 преобразуют строковое значение в тип данных varchar (MAX), поскольку это единственный способ создать строковое значение длиной более 8000 байтов. (В следующем разделе более подробно рассматривается varchar (MAX) .) При первом выборе из sys.dm_db_database_page_allocations значения PageType должны быть 1, 3 и 10. Во второй раз после вставки данных размером более 40 КБ вы также должны увидеть значения PageType, равные 4. PageType 3 указывает на страницу TEXT_MIXED , а PageType 4 указывает на страницу TEXT_DATA .
Хранение данных больших объектов в строке данных
Если вы храните все значения типов данных больших объектов вне обычных страниц данных, SQL Server необходимо выполнять дополнительное чтение страниц каждый раз, когда вы получаете доступ к этим данным, так же, как и для страниц с переполнением строк. В некоторых случаях вы можете заметить улучшение производительности, разрешив сохранять некоторые данные больших объектов в строке данных. Вы можете включить параметр таблицы с именем text in row для конкретной таблицы, установив для параметра значение «ON» (включая одинарные кавычки) или указав максимальное количество байтов, которое будет храниться в строке данных. Следующая команда позволяет хранить до 500 байт данных больших объектов вместе с обычными данными строк в таблице, называемой employee :
EXEC sp_tableoption employee, 'text in row', 500;
Обратите внимание, что значение указывается в байтах, а не в символах. Для данных ntext каждому символу необходимо 2 байта, чтобы любой столбец ntext сохранялся в строке данных, если он меньше или равен 250 символам. Когда вы включаете опцию text in row , вы никогда не получите только 16-байтовый указатель для данных больших объектов в строке, как в случае, когда опция не включена . Если данные в поле LOB больше указанного максимума, строка содержит корневую структуру, содержащую указатели на отдельные порции данных LOB. Минимальный размер корневой структуры составляет 24 байта, а возможный диапазон значений, которым может быть задан текст в строке, составляет от 24 до 7000 байтов. (Если вы укажете опцию «ON» вместо определенного числа, SQL Server примет значение по умолчанию 256 байтов.)
Чтобы отключить параметр текста в строке , можно установить значение «ВЫКЛ» или 0. Чтобы определить, имеет ли таблица свойство текста в строке , можно просмотреть представление каталога sys.tables следующим образом:
ВЫБЕРИТЕ имя, text_in_row_limit FROM sys.tables WHERE name = 'employee';
Это значение text_in_row_limit указывает максимальное количество байтов, разрешенное для хранения данных больших объектов в строке данных. Если возвращается 0, опция текста в строке отключена.
Теперь создайте таблицу, очень похожую на ту, которая просматривает структуры строк, но измените столбец varchar (250) на тип данных text . Вы будете использовать почти такой же оператор INSERT, чтобы вставить одну строку в таблицу:
CREATE TABLE HasText (Col1 char (3) NOT NULL, Col2 varchar (5) NOT NULL, Col3 text NOT NULL, Col4 varchar (20) NOT NULL); INSERT HasText VALUES («AAA», «BBB», REPLICATE («X», 250), «CCC»);
Теперь используйте запрос на распределение, чтобы найти основную информацию для этой таблицы и посмотрите на информацию sys.dm_db_database_page_allocations для этой таблицы (см. Листинг 8-2).
Перечисление 8-2, Находящее основную информацию для таблицы HasText
SELECT convert (char (7), object_name (object_id)) AS name, partition_id, partition_number AS pnum, строки, alloc_unit_id AS au_id, конвертируйте (char (17), type_desc) в качестве page_type_desc, всего_страниц AS-страниц FROM sys.partitions p JOIN sys .allocation_units a ON p.partition_id = a.container_id WHERE object_id = object_id ('dbo.HasText'); ВЫБЕРИТЕ alloc_page_file_id в качестве PageFID, alloc_page_page_id в качестве PagePID, object_id в качестве ObjectID, partition_id AS PartitionID, alloc_unit_type_desc в качестве AU_Type, page_type в качестве PageType FROM sys.dm_db_database_page_allocations (текстовый объект, dll_DID) ) имя partition_id pnum строк au_id page_type_desc страниц ------- ----------------- ---- ----- --------- -------- --------------- ----- HasText 72057594039435264 1 1 72057594044350464 IN_ROW_DATA 2 HasText 72057594039435264 1 1 72057594044416000 LOB_DATA 2 PageFID PagePID PagePID ObjectID PartitionID AU_Type PageType - ----- ------- -------- ----------------- ------------- - -------- 1 2197 133575514 72057594039435264 Данные большого объекта 3 1 2198 133575514 72057594039435264 Данные большого объекта 10 1 2199 133575514 72057594039435264 Данные в строке 1 1 2200 133575514 72057594039435264 Данные в строке 10
Вы можете видеть две страницы больших объектов (страница данных больших объектов и страница IAM больших объектов) и две страницы для данных в строке (опять же, страница данных и страница IAM). Страница данных для данных в строке - 2199, а данные большого объекта - на странице 2197. Следующий вывод показывает раздел данных при запуске DBCC PAGE на странице 2199. Структура строк очень похожа на структуру строк, показанную в главе 6. 6-6, за исключением самого текстового поля. Байты с 21 по 36 являются 16-байтовым текстовым указателем, и вы можете видеть значение 9508, начинающееся со смещения 29. Когда байты обращаются вспять, оно становится 0x0895 или 2197, что является страницей, содержащей текстовые данные, как вы видели в выводе в Перечислении 8-2.
Теперь давайте включим текстовые данные в строке длиной до 500 байт:
EXEC sp_tableoption HasText, «текст в строке», 500;
Включение этой опции не заставляет текстовые данные перемещаться в строку. Вы должны обновить текстовое значение, чтобы фактически вызвать перемещение данных:
ОБНОВЛЕНИЕ HasText SET col3 = REPLICATE ('Z', 250);
Если вы запустите DBCC PAGE на исходной странице данных, обратите внимание, что текстовый столбец размером 250 z теперь находится в строке данных, и что строка практически идентична по структуре строке, содержащей данные varchar, которые вы видели на рисунке 6- 6.
Последняя проблема при работе с данными больших объектов и параметром « текст в строке» связана с ситуацией, в которой текст в строке включен, но большой объект превышает максимальную настроенную длину для некоторых строк. Если вы измените максимальную длину для текста в строке на 50 для таблицы HasText, с которой вы работали, это также вынудит данные LOB для всех строк с более чем 50 байтами данных LOB немедленно удалиться со страницы, так же, как когда вы полностью отключите эту опцию:
EXEC sp_tableoption HasText, «текст в строке», 50;
Однако установка ограничения на меньшее значение отличается от отключения опции двумя способами. Во-первых, некоторые строки могут по-прежнему иметь данные больших объектов, которые находятся ниже предела, и для этих строк данные больших объектов полностью сохраняются в строке данных. Во-вторых, если данные больших объектов не помещаются, информация, хранящаяся в самой строке данных, не является просто 16-байтовым указателем, как это было бы, если бы текст в строке был отключен. Вместо этого, для данных больших объектов, которые не соответствуют определенному размеру, строка содержит корневую структуру для B-дерева, которое указывает на фрагменты данных больших объектов. Пока параметр текста в строке не имеет значения «ВЫКЛ» (или 0), SQL Server никогда не сохраняет простой 16-байтовый указатель большого объекта в строке. Он хранит либо данные больших объектов (если они подходят), либо корневую структуру для B-дерева данных больших объектов.
Корневая структура имеет длину не менее 24 байтов (поэтому 24 - это минимальный размер текста в пределе строки ), а значение байтов аналогично значению 24 байтов в указателе переполнения строк. Основное отличие состоит в том, что длина не сохраняется в байтах 12–15. Вместо этого байты 12–23 представляют собой ссылку на фрагмент данных больших объектов на отдельной странице. Если несколько корневых блоков доступны через корень, здесь может быть несколько наборов по 12 байтов, каждый из которых указывает на данные большого объекта на отдельной странице.
Как указывалось ранее, при первом включении текста в строке перемещение данных не происходит, пока текстовые данные не будут фактически обновлены. То же самое верно, если предел увеличен, то есть, даже если новый предел достаточно велик для размещения данных больших объектов, которые были сохранены вне строки, данные больших объектов не перемещаются в строку автоматически. Сначала вы должны обновить фактические данные больших объектов.
Помните, что даже если объем данных больших объектов меньше предела, данные не обязательно сохраняются в строке. Вы по-прежнему ограничены максимальным размером строки в 8 060 байт для одной строки на странице данных, поэтому объем данных больших объектов, которые можно сохранить в фактической строке данных, может быть уменьшен, если объем данных не больших объектов большой , Кроме того, если столбец переменной длины необходимо увеличить, он может вытолкнуть данные больших объектов со страницы, чтобы не превысить ограничение в 8 060 байт. Рост столбцов переменной длины всегда имеет приоритет над хранением данных больших объектов в строке. Если во время операции обновления поля char переменной длины не нужно увеличивать, SQL Server проверяет рост количества данных больших объектов в порядке смещения столбцов. Если один LOB должен расти, другие могут быть вытеснены из ряда.
Наконец, вы должны знать, что SQL Server регистрирует все перемещения данных больших объектов, что означает, что уменьшение предела или выключение опции « текст в строке» может быть очень трудоемкой операцией для большой таблицы.
Хотя большие столбцы данных, использующие типы данных больших объектов, могут храниться и управляться очень эффективно, использование их в таблицах может быть проблематичным. Данные, хранящиеся в виде текста, ntext или изображения, не всегда можно манипулировать с помощью обычных команд манипулирования данными, и во многих случаях вам нужно прибегнуть к использованию операций readtext, writetext и updatetext , которые требуют обработки смещений байтов и значения длины данных. До выпуска SQL Server 2005 вы должны были решить, следует ли ограничить столбцы максимум 8000 байтами или работать с большими столбцами данных, используя операторы, отличные от тех, которые вы использовали для более коротких столбцов. Начиная с версии 2005, SQL Server предоставляет решение, которое дает вам лучшее из обоих миров, как вы увидите в следующем разделе.
Хранение данных MAX-длины
SQL Server 2005 и более поздние версии предоставляют возможность определения поля переменной длины со спецификатором MAX . Хотя эта функциональность часто описывается с помощью ссылки только на varchar (MAX) , спецификатор MAX также может использоваться с nvarchar и varbinary . Вы можете указать спецификатор MAX вместо фактического размера, когда используете один из этих типов для определения столбца, переменной или параметра. Используя спецификатор MAX , вы оставляете за SQL Server возможность определять, сохранять ли значение как обычное значение varchar, nvarchar или varbinary или как LOB. В общем, если фактическая длина составляет 8000 байт или меньше, значение обрабатывается так, как если бы оно было одним из обычных типов данных переменной длины, включая возможное переполнение на страницах переполнения строк. Тем не менее, если столбец varchar (MAX) действительно нуждается в разливе страницы, необходимые дополнительные страницы считаются страницами больших объектов и показывают большой объект IAM_chain_type при проверке с использованием DBCC IND . Если фактическая длина превышает 8000 байт, SQL Server сохраняет и обрабатывает значение точно так, как если бы оно было текстовым, текстовым или графическим . Поскольку столбцы переменной длины со спецификатором MAX обрабатываются либо как обычные столбцы переменной длины, либо как столбцы больших объектов, особого обсуждения их хранения не требуется.
Размер значений, указанных с помощью MAX, может достигать максимального размера, поддерживаемого данными больших объектов, который в настоящее время составляет 2 ГБ. Однако, используя спецификатор MAX , вы указываете, что максимальный размер должен быть максимальным, поддерживаемым системой. Если вы обновите таблицу со столбцом varchar (MAX) до будущей версии SQL Server, длина MAX станет такой, какой будет новый максимум в новой версии.
Добавление данных в столбец LOB
В механизме хранения каждый столбец больших объектов разбивается на фрагменты, максимальный размер которых составляет 8 040 байт каждый. Когда вы добавляете данные к большому объекту, SQL Server находит точку добавления и просматривает текущий фрагмент, в который будут добавлены новые данные. Он рассчитывает размер нового фрагмента (включая недавно добавленные данные). Если размер превышает 8 040 байт, SQL Server выделяет новые страницы больших объектов до тех пор, пока не останется фрагмент размером менее 8 040 байт, а затем находит страницу, на которой достаточно места для оставшихся байтов.
Когда SQL Server выделяет страницы для данных больших объектов, у него есть две стратегии размещения:
Для данных размером менее 64 КБ случайным образом выделяется страница. Эта страница происходит от степени, которая является частью IAM большого объекта, но не гарантируется, что страницы будут непрерывными.
Для данных, размер которых превышает 64 КБ, он использует распределитель страниц только для добавления, который выделяет один экстент за раз и непрерывно записывает страницы в экстенте.
С точки зрения производительности, полезно писать фрагменты размером 64 КБ за раз. Выделение 1 МБ заранее может быть полезным, если вы знаете, что размер будет 1 МБ, но вам также необходимо учитывать пространство, необходимое для журнала транзакций. Если вы сначала создаете фрагмент размером 1 МБ с произвольным содержимым, SQL Server регистрирует 1 МБ, а затем также регистрируются все изменения. Когда вы выполняете обновления данных больших объектов, новые страницы выделять не нужно, но изменения все равно нужно регистрировать.
Пока значения больших объектов малы, они могут находиться на странице данных. В этом случае, некоторое предварительное распределение может быть хорошей идеей, чтобы данные больших объектов не становились слишком фрагментированными. Общая рекомендация может состоять в том, что если объем данных, которые нужно вставить в столбец большого объекта за одну операцию, относительно мал, вам следует вставить большое значение объекта конечного ожидаемого значения, а затем при необходимости заменить подстроки этого начального значения. , Для больших размеров попробуйте добавить или вставить кусками по 8 * 8040 байт. Таким образом, каждый раз выделяется целый экстент, и на каждой странице хранится 8040 байт.
Если вы обнаружите, что данные больших объектов становятся фрагментированными, вы можете использовать ALTER INDEX REORGANIZE для дефрагментации этих данных. Фактически, эта опция ( WITH LOB_COMPACTION ) включена по умолчанию, поэтому вам просто нужно убедиться, что вы не установили для нее значение «OFF» .