Кошмар SEO: когда NoIndex становится плохим

В нужное время и место тег noindex может быть прекрасной вещью К сожалению, бывают случаи, когда это может вызвать проблемы.
За последние несколько лет мне довелось поработать на нескольких сайтах, число страниц которых исчисляется сотнями миллионов. Причин, по которым люди позволяют своим сайтам расти до таких размеров, много и они различны. Вот некоторые из наиболее распространенных причин, почему это в конечном итоге происходит:
- Издатель пытается максимизировать свою способность ранжироваться на условиях длинного хвоста.
- Издатель считает, что предлагать огромный уровень доработок хорошо для удобства пользователей.
- Сайт использует систему тегов без ограничений, которая позволяет использовать любую комбинацию тегов (даже явно нелогичные) для создания уникальных новых страниц.
- Реализация сайта содержит ошибки, которые приводят к непреднамеренному созданию страниц.
Когда сайты становятся такими большими, это часто означает, что многие страницы имеют очень небольшую ценность для погашения или что различия между группами страниц в данном разделе почти тривиальны.
Рассмотрим, например, страницу «Виджеты для стирки синих бутылочек 10-го размера» и «Виджеты для стирки зеленых левых бутылок 10-го размера». Пользователи могут захотеть выбрать свой цвет, но для этого не нужно создавать совершенно новая веб-страница. Я видел ситуации, когда отношение общего количества страниц к полезным страницам достигает 10: 1!
Проблема с наличием таких страниц заключается в том, что это может привести к тому, что Google пометит ваш сайт как тонкий контент , Это может означать потерю видимости из-за Алгоритм панды или даже ручной штраф. Ничто из этого не является хорошей вещью!
Noindexing не ответ
Один из способов избежать штрафного сценария - поставить тег noindex на страницах, которые вы не хотите включать в индекс Google. Предполагая, что вы можете идентифицировать все страницы, которые могут вызывать беспокойство Google, это устранит риск ручного штрафа или попадания в алгоритм Panda, но этого недостаточно. Давайте рассмотрим три основные причины:
1. Разведение фокуса PageRank. Один из распространенных сценариев заключается в том, что «плохие» страницы связаны в списке товаров.
Когда это обрабатывается должным образом, ссылки в этом списке указывают на страницы, которые очень тесно связаны и очень релевантны той странице, на которой находятся ссылки и которая стоит индексировать, как показано здесь:
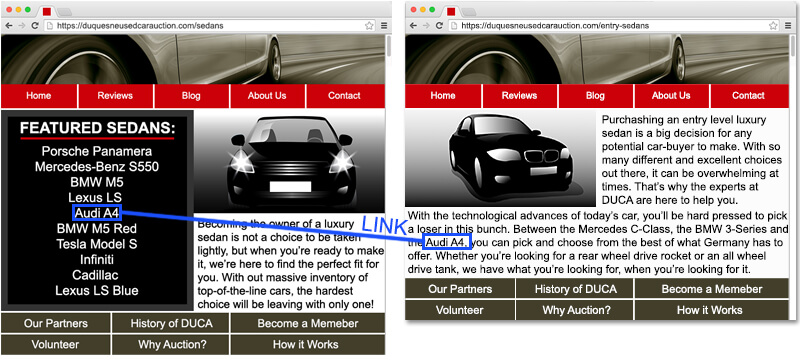
Теперь есть вероятность, что на каждой странице вашего сайта будут ссылки, указывающие на вашу домашнюю страницу, вашу страницу «о нас», вашу страницу «свяжитесь с нами», политику конфиденциальности и другие менее тематически ориентированные страницы, такие как эти.
Не поймите меня неправильно, эти ссылки являются важной частью структуры вашего сайта, поэтому иметь их там хорошо. Тем не менее, ссылки на эти страницы продукта в тематически актуальном навигационном пути («Актуальные ссылки на страницы с ключевыми деньгами») действительно ценны. Вы не хотите тратить их впустую.
Проблема начинается, когда некоторые ссылки в списке продуктов являются страницами, которые не заслуживают индексации. Вы можете решить проблемы, связанные со штрафом, с помощью тега noindex, но в итоге вы теряете часть этого PageRank. Вот пример страницы, чтобы проиллюстрировать проблему:
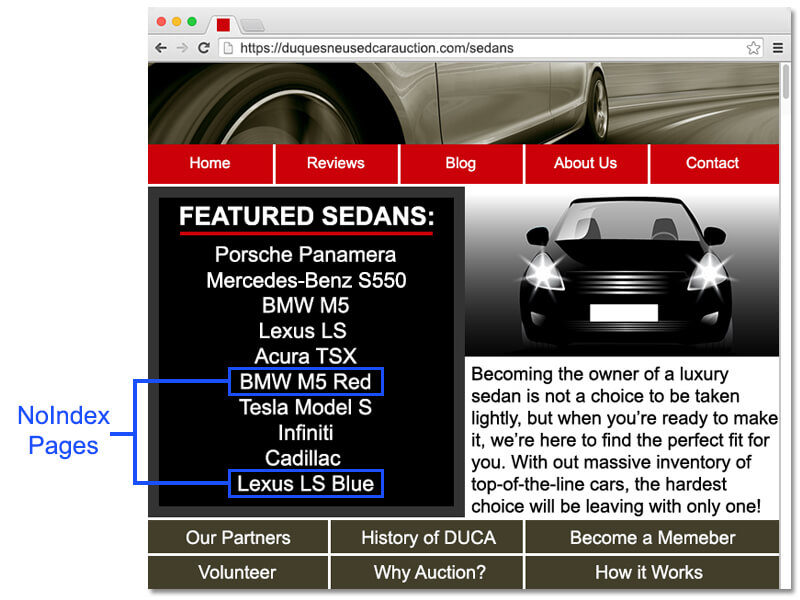
На приведенном выше примере 20% наших тематически релевантных ссылок на страницы с ключевыми деньгами указывают на страницу без индекса. Этот PageRank в основном полностью впустую. Зачем? Давайте посмотрим, что происходит на этой странице без индекса:
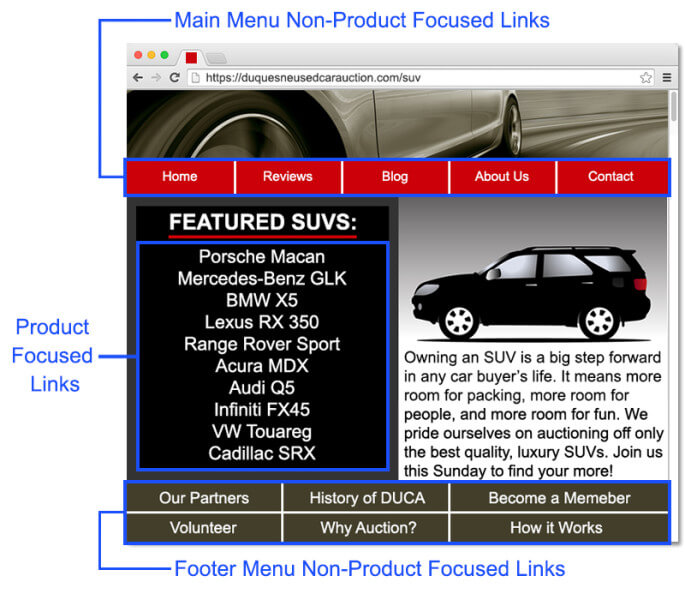
Часть PageRank используется самой страницей без индекса, и хотя страница без индекса все еще может передавать оставшуюся часть PageRank на другие страницы по ссылкам, подавляющее большинство этих ссылок переходят на страницы, отличные от страниц с ключевыми деньгами, поскольку Я показал в примере изображения выше.
2. PageRank прошел в никогда-никогда не приземлиться. Потеря PageRank из тематически релевантных ссылок на ключевые денежные страницы - это достаточно плохо, но это не единственная проблема. На очень больших сайтах может возникнуть ситуация, когда Google не сканирует весь ваш сайт, как показано здесь:
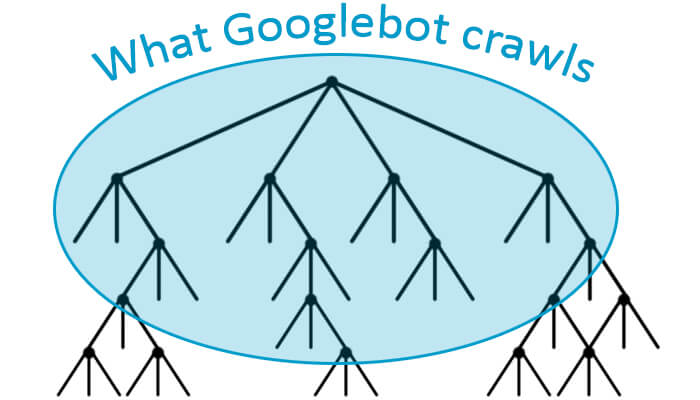
Как показано на этом изображении, Google достигает точки, где сканирование прекращается. Он просто решил, что на сайте слишком много страниц, чтобы идти дальше. Тем не менее, страницы в нижней части дерева, где прекращается сканирование, по-прежнему передают свой PageRank другим страницам, которые Google не сканирует и не будет сканировать. Этот PageRank фактически передается в никогда-никогда землю, и это также впустую.
3. Обостряет пропускную способность сканирования. Google по-прежнему сканирует страницы с тегом NoIndex на странице. Если у вас большой процент страниц на вашем сайте, которые не индексируются, Google будет тратить время на сканирование этих страниц вместо того, чтобы сканировать страницы, которые он может на самом деле присвоить вам.
Это может повредить вам, когда вы вносите серьезные изменения на своем сайте, которые вы хотите, чтобы Google видел и обрабатывал, или когда вы добавляете новый раздел на сайт. Для большинства сайтов Google сканирует только небольшую часть сайта в определенный день, поэтому если они тратят время на часть своего «бюджета сканирования» на страницах, которые не имеют для них никакого значения, это может значительно замедлить процесс обнаружения отличного контента. новые изменения, которые вы сделали.
Rel = канонический не очень хорошо либо
Альтернативным решением для тега NoIndex является реализация Google отн = каноническое тег, чтобы сообщить Google, что данная страница должна рассматриваться как копия или подмножество другой страницы. В принципе, это здорово, потому что он сохранит весь PageRank, связанный со страницей, и передаст его обратно на страницу, на которую ссылается тег. Есть две проблемы с этим:
- Rel = canonical предназначен для использования только в тех случаях, когда страница с тегом является точной копией или подмножеством страницы, на которую ссылается тег. Использование его в ситуациях, когда это не так, не рекомендуется.
- Даже если страницы, с которыми вы пытаетесь работать, являются строгими подмножествами страниц, которые вы хотите сохранить, Google считает rel = canonical предложением и может предпочесть проигнорировать это предложение. К сожалению, это не так уж редко, и по моему опыту часто случается в таких очень больших ситуациях на веб-сайте.
Иногда нужно просто укусить пулю
Иногда вам просто нужно взять на себя задачу навести порядок. Он также может приносить огромные дивиденды, как показано на этой диаграмме трафика:
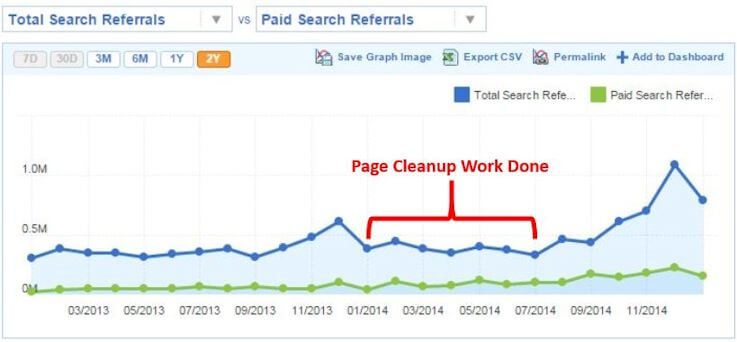
Мы сократили количество страниц на этом сайте более чем на 90%, с сотен миллионов страниц до десятков миллионов. Похоже, Google понравилось!
Значительные усилия по развитию будут необходимы для того, чтобы исправить ситуацию такого рода; однако мой опыт показывает, что награды обычно оправдывают усилия.
Мнения, выраженные в этой статье, принадлежат автору гостя и не обязательно относятся к Search Engine Land. Штатные авторы перечислены Вот ,